
Marking: For this assignment, the software is worth 60% and the documentation 40%. Software that does not build and execute on lockhart will receive 0%. The report does not have to be beautifully bound, but should be presentable and not be hand written.
Note: Special thanks to Dave McCaughan for the basis of this assignment, and the parallaldo generator program.
"Where's Waldo?" is a popular series of books (ostensibly for children) in which they are challenged to find a particular character in a very complex picture. From a computational point of view, this can be seen as a form of template matching, in which we attempt to locate a region of a larger space which matches some small template example. This is easiest to visualize with images where the problem becomes one of finding a region of a larger image which matches a small exemplar pattern.
For this assignment, you will implement a parallel version of a template matching algorithm in which a large number of images are scanned in order to locate a smaller number of template images (called
In the example below, the parallaldo is found in two places (red) in the image, the second being a 90-degree clockwise rotation of the template.
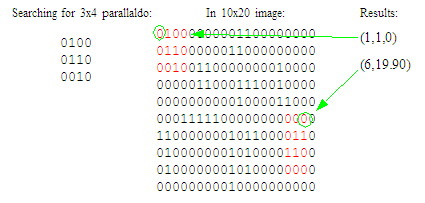
Note how the findings are reported: (y,x,r) where (y,x) denotes the location in the image of the (unrotated) template's upper left corner, and r being the degrees of clockwise rotation. The convention of the first coordinate being the row (here numbered starting from 1) is normal for graphics and matrix data. Of course, you can store the data in memory however you want.
Also note the opportunity for ambiguity: If the parallaldo is symmetrical--which is true for the example--it could be validly matched in any of 2 or even 4 rotations. That is, (1,1,0) is the same finding as (3,4,180), and (6,19,90) is the same as (9,17,270).
For the purpose of further simplifying the program, we'll make the following rules:
These rules will insure determinism: that there is only one correct result for any pair of parallaldo and image files, regardless of how you write your search algorithm. Furthermore, if your program finds a match, it can terminate its search immediately without looking for additional matches or other rotations of the same parallaldo in the current image.
Data will be furnished in two directories, one containing candidate parallaldos for which to search, the other images in which to search. Your program will search for every combination of parallaldo and image pairs.
The directories will be populated with text files consisting of a header line giving the dimensions of the rectangular image in R rows x C columns, followed by R rows of C 1s and 0s. Your program may assume that all files in the specified directories are intended as input.
To help with testing, you can find in Public Documents on lockhart the following files:
NOTE: Your program should be capable of running in serial fashion when it is started with only one thread. This is not difficult to arrange if you plan it from the start. We need to have timing from a serial version in order to calculate speedup.
The search algorithm is completely up to you. It can be as "brute force" or as clever as you want. There are several places where parallelism can be exploited (suggestions below).
The program should be called
Print an error message and abort if the arguments are invalid, or if either directory is empty.
The cores argument is intended to reflect the number of cores in use for computation. Depending on your work allocation methodology, your main thread may be doing some non-CPU intensive I/O and supervision and then just waiting for the worker threads to join, in which case it does not need to be counted as a core. This means that with an argument of 8, for example, you could create 8 worker threads, or make a thread pool of size 8. This cores argument will later be used as the X axis on your graphs, so you should be clear what it represents.
What about cores > 16? This can happen if you are intentionally "oversubscribing" the physical cores. A legitimate use for this in a scalable program could be appointing threads to read files (which assumes they will mostly be blocked on I/O and hardly occupy a core). If you do all your file reading in the main thread, this comment does not apply, and you should only oversubscribe to see for yourself if/how it affects the performance.
The output of aldo is printed on stdout, where it can be captured in a log file using the command redirection operator ">". Start each line of result output with the character "$" so that meaningful output can be readily grepped out from among any other lines printed (e.g., in case you inserted printf's for debugging).
Each match is printed on a separate line using the following format
where parfile and imfile are the bare filenames (no directory path) of the parallaldo and its matching image, respectively, and (y,x,r) are bracketed integers printed without extra spaces or leading zeroes. Thus, the result line will have
End with a report of total elapsed time in seconds to at least 2 decimal places. This should be the final line printed on stdout.
The sample file
You're under no obligation to follow any of these suggestions. If you can think of a faster way to do something, go for it.
One way to structure the program is to start by reading all the parallaldos into memory (since there aren't a lot of them and they are small). The program can then have a main loop that reads in each target image (some of which are quite large), and an inner loop that searches for each parallaldo in turn. Note that when you find a match, you can break out of the inner loop and go on to the next image.
Opportunities for exploiting data parallelism include:
Consider carefully how you can overlap (slow) disk I/O operations with (fast) computation. One popular technique is known as "double buffering." This is where you are reading one image file into a buffer while the processor(s) are searching through another image already read in. There are a couple ways of approaching this. One is to use an asynchronous read (you start the read, then check the status later to see if it finished); another is to devote a separate thread to do a normal synchronous read (while it blocks, other threads are carrying on so no CPU time is wasted).
Keep load balancing in mind, because the image sizes vary greatly. Furthermore, if you find a match, the search could terminate quickly; but if you don't, you'll have to run right through the entire image.
Anyway, the trick is to find useful work to keep all 16 cores busy, thus reducing idle time. Generally speaking, the higher/coarser levels of parallelism will be easier to program, so if you can occupy all the cores that way it's good enough, and there may be nothing to be gained by parallelizing at the lowest/fine-grained level.
Code your solution to run on lockhart using Java 8 in NetBeans according to the program specification below. Don't forget that Parallel Amplifier claims to work with Java. It might help you optimize your program.
You can assume that the maximum no. of cores is 16, for the purpose of defining static data structures. As mentioned above, you may choose to spawn additional threads that are not for computation.
For this assignment, we will time the entire execution from start to finish. There are several ways to carry out execution timing in Java. We will use
Same terms as for A2, but no rematch provision. For contest purposes this time, we'll take 5 timings, throw out the worst one, and average the rest.
Marks for Assignment #2 Part 2
For the software, mark is 0-6 based chiefly on functionality:
6 = Parallel program that produces correct results and reports timings for any tested args
1.5-5.5 = Same as 6, but with deductions according to deficiencies
1 = Parallel program that runs cleanly, and is coded to address the problem, but results are all incorrect or missing
0 = Fails to build, or crashes without producing any results
In addition, 1/2 mark penalties will be deducted for specific "sins": numerous Java warnings, file headers missing/incomplete, program name wrong, Java errors printed at run time.
The documentation starts with 4 marks, then deduct 1 mark for any item missing, or 1/2 mark for any lame or poorly-done item. If you didn't have any working software to graph, you'll lose at least 1 mark to be fair to those who conducted timing and produced their graphs.